From Labs to Daily Life: The Rise of Specialized AI Hardware ,From real-time translation on smartphones to model training in data centers, from ray tracing in gaming to environmental perception in autonomous driving—a single type of hardware can no longer handle the diverse demands of modern computing. The era of the CPU as a "one-size-fits-all" solution is gradually giving way to an age ofheterogeneous computing, where CPUs, GPUs, TPUs, and NPUs eachcarve out their own niches, collectively forming the hardware foundation of the AI era.

In-Depth Analysis: Technical Characteristics and Application Scenarios of the Four Processor Types
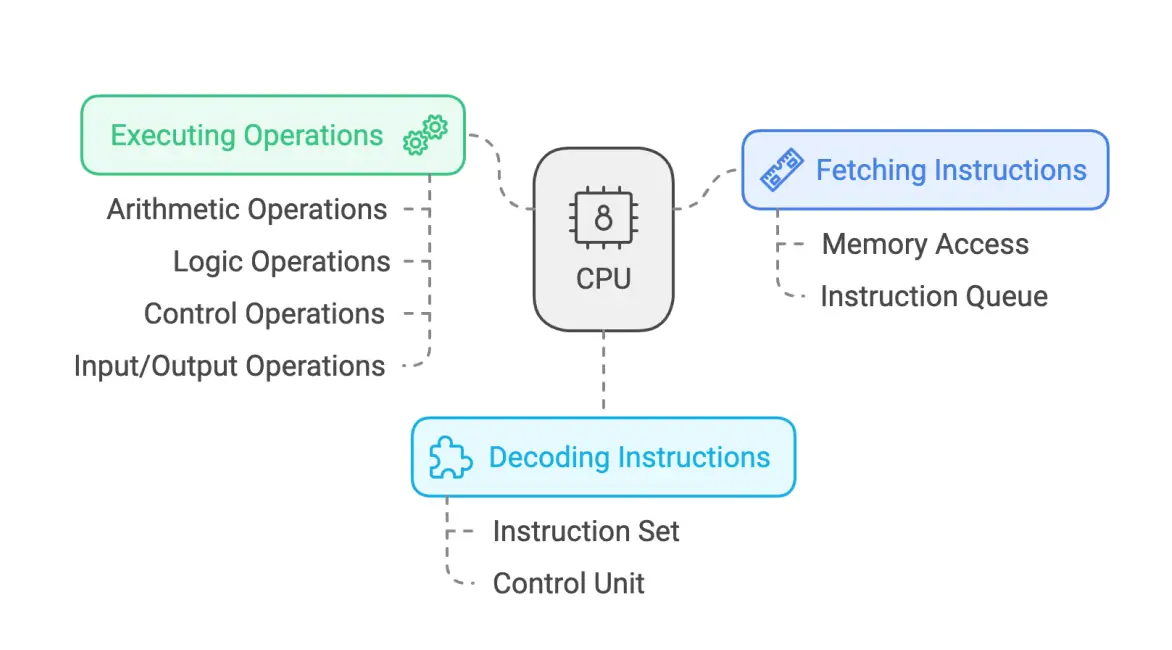
1. CPU: The "Command Center" of General-Purpose Computing
Core Positioning: As the "brain center" of computers, the CPU handles critical tasks such as instruction scheduling and system management. It excels at processing complex single-threaded workloads—including logical operations and serial computation—serving as the foundational computing unit in all devices.
Architecture Design: Typically equipped with 2 to 64 high-performance cores (e.g., Intel Xeon’s 28-core design), CPUs commonly operate at base clock speeds of 3–5 GHz, optimized for single-thread performance. Their multi-level cache hierarchy (L1/L2/L3) enables rapid response to temporary data demands.
Performance Characteristics: While CPUs demonstrate relatively low efficiency in parallel AI tasks (with single-precision GFLOPS typically ranging from tens to hundreds), they maintain balanced power efficiency and remain suitable for supporting small-scale AI inference—such as running simple classification models via Python scripts.
Typical AI Scenarios: Ideal for training large-scale models such as Convolutional Neural Networks (CNNs) and Transformers (e.g., training a 1-billion-parameter image generation model), as well as large-scale data-parallel processing (e.g., handling million-image datasets). Seamlessly supports mainstream frameworks like TensorFlow and PyTorch.
Limitations & Suitability: Less efficient in serial tasks (e.g., performance is underutilized when running office software) and relatively power-intensive (high-end models can exceed 400W). Best deployed in fixed-power environments such as data centers and AI research labs. Leading products include NVIDIA A100/H100 and AMD MI300 series.
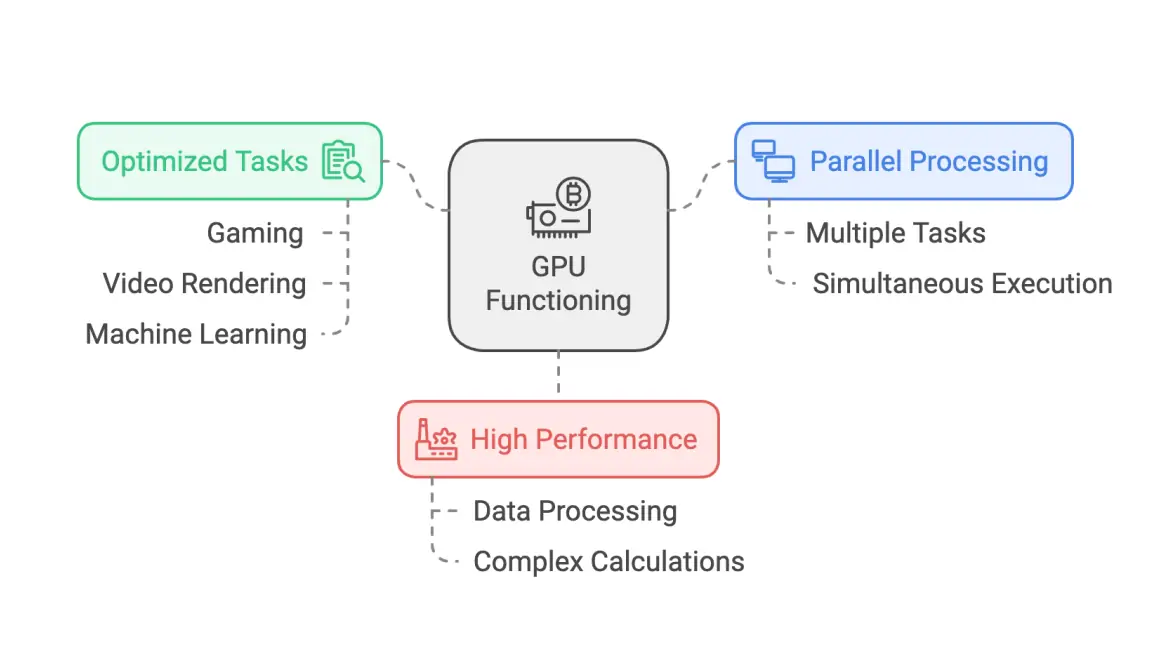
2. GPU: The "Powerhouse" of Parallel Computing
Core Positioning: Originally designed for graphics rendering, GPUs have now become the workhorse for AI training and parallel computation. They excel at processing thousands of simple tasks simultaneously—such as pixel calculations and matrix operations—serving as the fundamental infrastructure for deep learning.
Architecture Design: Featuring a "many-core" architecture, models like those in the NVIDIA RTX 50 series based on the Blackwell architecture are equipped with over 20,000 CUDA cores. Combined with Tensor Cores that support FP16/FP8 mixed-precision computing, they significantly enhance AI training efficiency.
Performance Breakthrough: The RTX 50 series achieves an 8x performance leap through DLSS 4 technology, with single-card AI computing power reaching hundreds of TFLOPS. Meanwhile, AMD's RDNA 4 architecture GPUs are rapidly catching up within open-source ecosystems (such as ROCm), emerging as a viable option for cross-platform AI training.
Typical AI Scenarios: Well-suited for training large-scale models like Convolutional Neural Networks (CNNs) and Transformers (e.g., training a 1-billion-parameter image generation model), as well as large-scale data-parallel processing tasks such as handling million-image datasets. Seamlessly compatible with mainstream AI frameworks including TensorFlow and PyTorch.
Limitations & Suitability: Less efficient for serial processing tasks (resulting in performance waste for routine office applications) and relatively high power consumption (high-end models can exceed 400W). Best deployed in fixed-power environments like data centers and AI research labs. Leading products include the NVIDIA A100/H100 and AMD MI300 series.
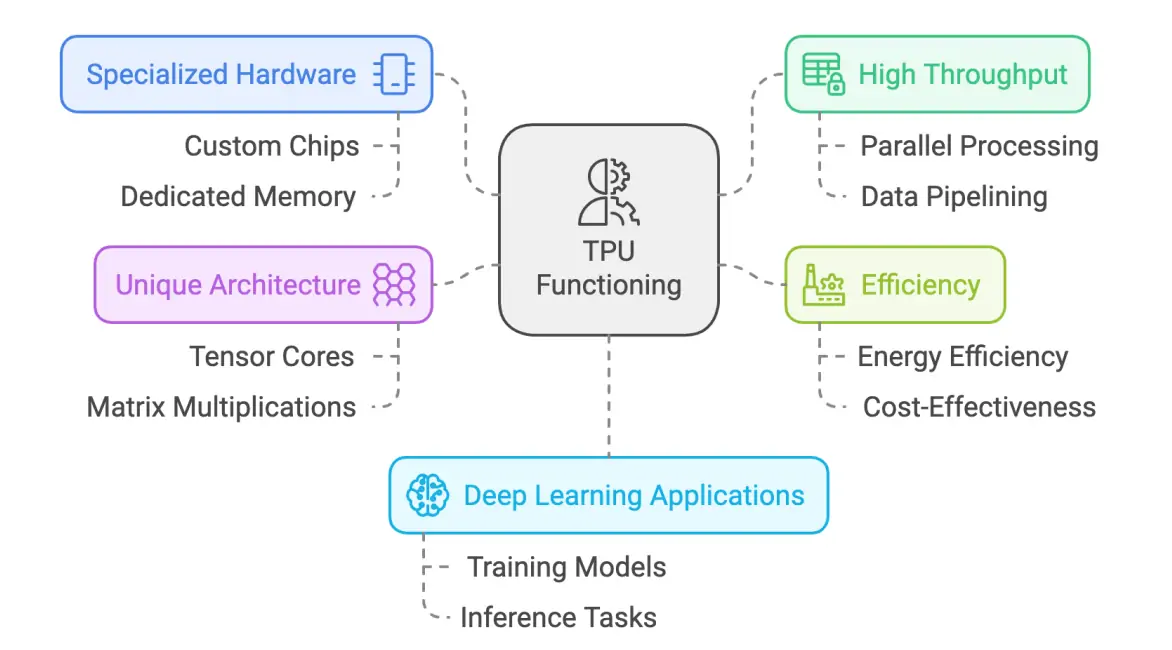
3. TPU: The Custom-Built Engine for Cloud AI
Core Positioning: Google's TPU (Tensor Processing Unit) is a custom-designed accelerator specifically optimized for machine learning workloads, serving as the driving force behind its search engine and large-scale model training. The 2025 Ironwood TPU v7 delivers a remarkable 4,614 TFLOPS of computational power.
Architecture Design: Deeply optimized for the TensorFlow framework, TPUs integrate large-scale Matrix Multiply Units (MXUs) and leverage 8-bit integer (INT8) / 16-bit bfloat16 (BF16) precision. This design sacrifices some general-purpose flexibility to achieve breakthrough efficiency in AI computation.
Energy Efficiency Advantage: Compared to comparable GPUs, TPUs demonstrate 30–80% better performance per watt for AI workloads. When training models like BERT or GPT-2, they significantly reduce power consumption and cooling demands in data centers.
Typical AI Scenarios: Optimized for large-scale model training in the cloud (e.g., iterative optimization of Google Gemini) and high-throughput inference tasks (such as real-time semantic analysis in search engines). Exclusively supports Google's ecosystem of AI toolchains.
Limitations & Suitability: Highly specialized with limited versatility (incapable of graphics rendering or general-purpose computing). Only accessible via Google Cloud, making it suitable primarily for enterprises deeply integrated with the Google ecosystem (e.g., AI recommendation systems for YouTube).
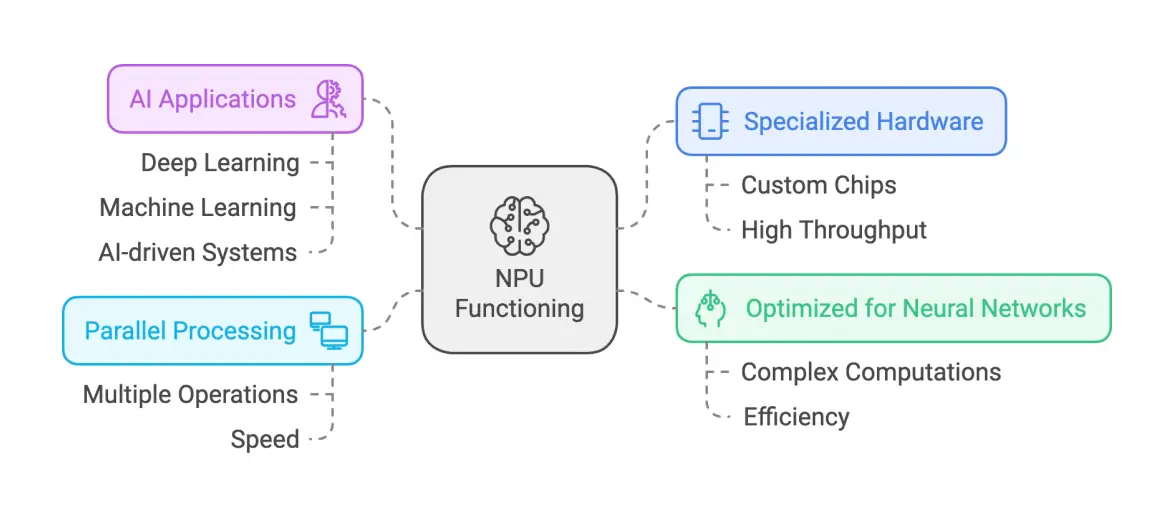
4. NPU: The "Energy-Saving Specialist" for On-Device AI
Core Positioning: Specifically designed as an AI processor for edge devices (such as smartphones and IoT equipment), NPUs focus on real-time inference in low-power scenarios. The 2025 flagship smartphone NPUs (like the Hexagon NPU in Snapdragon 8 Elite) achieve a 45% improvement in energy efficiency compared to the previous generation.
Architecture Design: Mimicking the neural connection patterns of the human brain, NPUs integrate dedicated Multiply-Accumulate (MAC) units and high-speed cache memory. Supporting low-precision computation formats like INT4 and FP8, they enable efficient inference within strict power constraints.
Performance Characteristics: While delivering computational power of several tens of TOPS (trillions of operations per second) per chip, NPUs consume only a few watts (typically around 2-5W in smartphones). This allows them to support real-time tasks—such as completing facial feature matching within 100 milliseconds.
Typical AI Scenarios: Enables on-device AI capabilities such as iPhone Face ID recognition and Huawei's AI photography enhancement; supports edge device inference including abnormal behavior detection in smart cameras and heart rate anomaly alerts in smartwatches; facilitates automotive cabin voice interactions like real-time command recognition.
Limitations & Suitability: Incapable of handling model training due to insufficient computational power, exclusively supports inference tasks, and relies on device manufacturers' software ecosystems (e.g., Apple Core ML, Qualcomm SNPE). Commonly found in consumer electronics, including Apple Neural Engine and Samsung Exynos NPU.
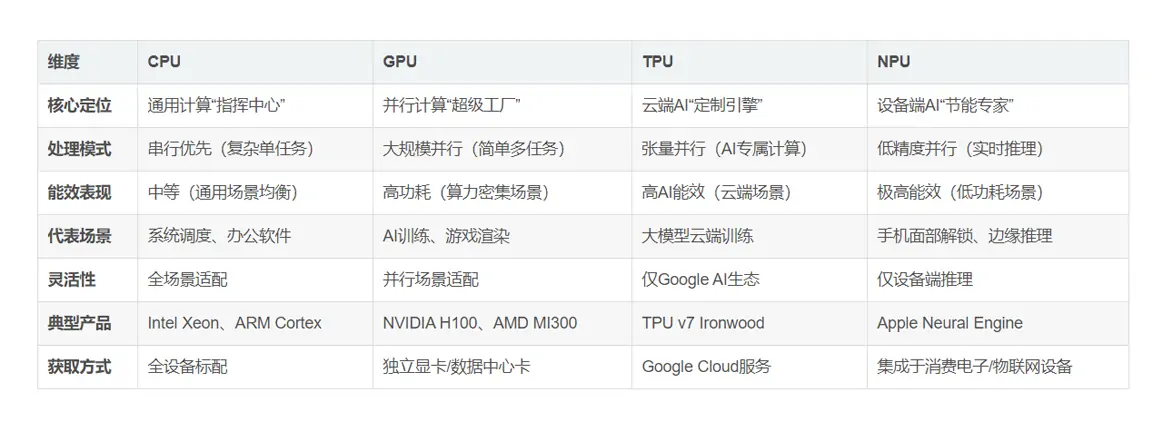
Horizontal comparison: Table of key differences among four types of processors
Scenario-Based Selection: Matching Hardware to Your Needs
Selecting by Task Type
General-Purpose Daily Tasks: Prioritize CPUs Whether launching a browser, running office software, or coordinating device hardware (e.g., controlling fan speed), CPUs remain the optimal choice due to their serial processing capabilities and versatility.
AI Training/Large-Scale Parallel Computing: Opt for GPUs or TPUs For training models with tens of millions of parameters or more (e.g., ResNet, GPT), leverage GPUs (framework-agnostic) or TPUs (Google ecosystem-specific). If simultaneous graphics rendering is required (e.g., game engine development), GPUs are the only viable option.
On-Device Real-Time AI: NPUs Are Essential Mobile devices like smartphones and smartwatches require real-time inference under low power consumption (e.g., voice assistant activation). NPUs offer unmatched energy efficiency in such scenarios.
Multi-Hardware Collaboration Cases
In modern systems, these four hardware types often operate inspecialized collaboration:
AI Workstation: The CPU handles task scheduling (e.g., allocating data loading and model saving tasks), the GPU accelerates parallel computation for model training, and theSSDenables high-speed data read/write. Together, they maximize training efficiency through seamless integration.
Smartphone: The CPU manages system resources (e.g., coordinating camera hardware), while theNPUprocesses real-time AI tasks (such as scene recognition and beauty filters during photography). Their cooperation delivers a low-latency user experience.
Autonomous Vehicle: The CPU or chestrates vehicle control logic, the GPU processes multi-camera image stitching, the NPU performs edge inference for real-time pedestrian/traffic light detection, and the TPU(cloud-based) periodically optimizes recognition models. This creates a closed-loopedge-cloud collaborationsystem.
Specialized Roles and Future Trends in AI Hardware
The CPU serves as the universal foundation, supporting basic operations across all devices. The GPU, with its massive parallel computing power, acts as the workhorse for both AI training and graphics processing. The TPU specializes in large-scale model training within the Google ecosystem, while the NPU brings AI from the cloud directly into our daily lives—powering everything from smartphones and watches to automobiles.
Looking ahead, as AI applications continue to evolve, hardware specialization will become even more refined. We may see chips designed specifically for robotics or "edge-training chips" that combine the strengths of NPUs and GPUs. Yet, through all these developments, one principle will remain central:matching hardware to specific scenarios. Choose the CPU for general tasks, the GPU for parallel computing, the TPU for cloud-based large models, and the NPU for on-device inference.











